前嗅ForeSpider脚本教程-链接抽取:应用场景及链接在源码的html标签里写脚本
今天,小编给大家带来的教程为:前嗅ForeSpider脚本教程中,链接抽取的应用场景,以及链接在源码的html标签里写脚本的实战教程。具体内容如下:
一.应用场景
当需要手动添加链接时,可添加链接脚本。
在“链接脚本处”,可能用到的类为extractor 、result、url、grabDoc、dom。
二.链接在源码的html标签里
链接地址可在源码中查找到。在目标网页右键,选择“查看源代码”,键盘点击“ctrl F”,查找目标链接所在位置。目标链接存在于标签中。
1.链接需要循环
场景:比如翻页等规律相同的一系列目标链接,存在于一个大的ul标签或者div标签里。
示例:获取CSDN首页文章列表链接。
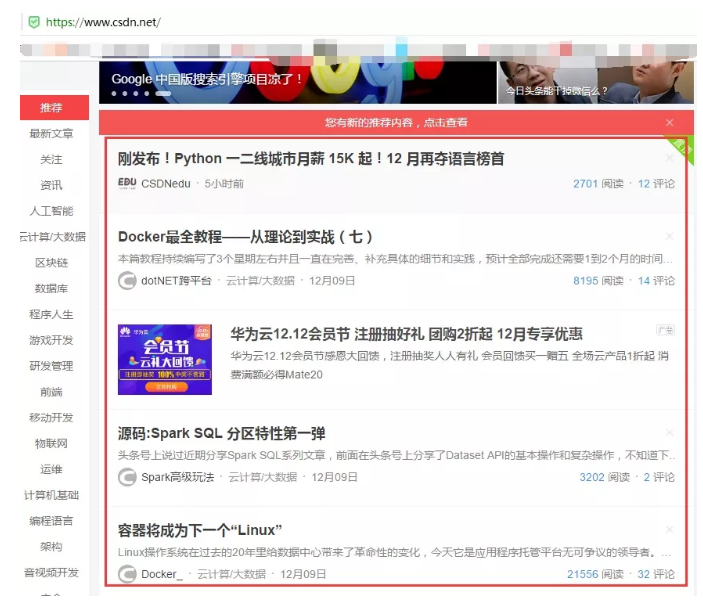
在该网页右键选择“查看源文件”,查找第一条链接的链接地址,定位目标数据位置。
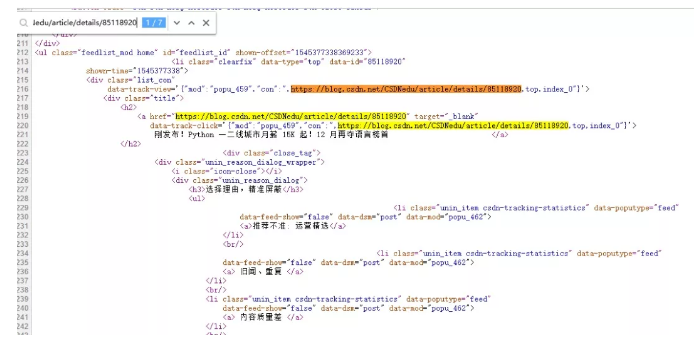
将该源码粘贴到notepad 中,选择语言为html,搜索目标数据的所在位置“ul”标签的id值。
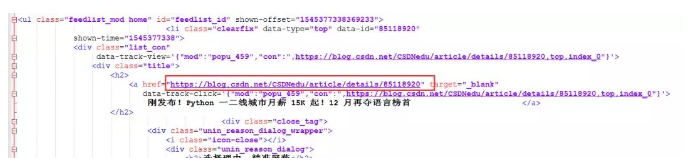
由图可知,列表页文章链接位于每个li中的a标签的href中。
脚本实例:暂无。
2.链接不循环
场景:获取更多链接,链接不像翻页那页具有自增性的规律。
示例:获取该网站更多的招标公告信息。
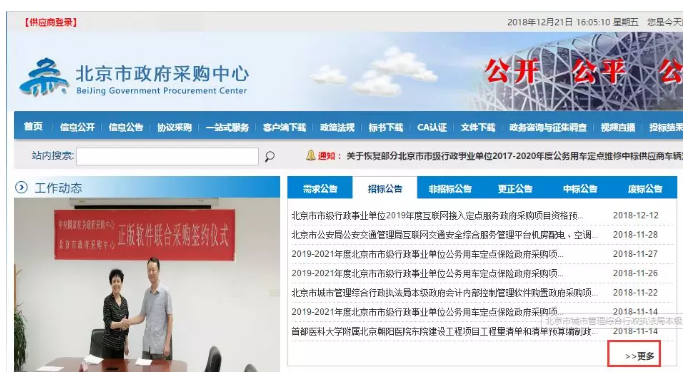
获取更多的招标公告信息,需要点击“更多”按钮。在该网页右键选择“查看源文件”,定位链接所在位置。

因标签名,和父级
的class属性都在多处存在,因此需要再向上查找节点,直到id为tab2-list的。
脚本实例:
var div = DOM.FindId(“tab2-list”);//先查找div
var a = DOM.FindClass(“more”,”a”,div );//从上一行找到的div开始查找,class属性为more的a标签。
url u;
u.urlname = “http://www.bgpc.gov.cn” a.href; //拼接完整的链接地址
u.title = “更多”; //填写title
u.entryId = CHANN.id;
u.tmplId = 2;
RESULT.AddLink(u);



